
È la prima domanda di chi pubblica un sito senza essere pratico di indicizzazione sui motori di ricerca: Perché il mio sito non esce sui motori di ricerca? Cominciamo ad analizzare i primi problemi che possono impedire al bot di Google di scansionare correttamente i nostri contenuti.
È la cosa più frustrante che esista: pubblicate un nuovo sito e quello non ne vuole sapere di uscire fuori su Google. In realtà la questione non è banale, posizionare un sito nelle prime pagine della SERP (la pagina dei risultati di Google) non è una cosa semplice e può richiedere investimenti importanti. Ma che fare se il nostro sito viene proprio ignorato dai motori di ricerca?
La prima da cosa da fare è capire se realmente c’è un problema tecnico, è verificare se Google vede il nostro sito. Come fare? Basta digitare
site:
ilmiosito.it
Se non uscirà fuori nulla o al massimo una o due pagine, allora si, c’è un problema di crawling, ovvero qualcosa sta dicendo ai sistemi di scansione automatici di Google di non indicizzare il sito. In questo caso, è bene rivolgersi alla Search Console di Google, lo strumento a cui sottoporre la sitemap del nostro sito e attraverso cui controllare se ci sono degli errori di scansione. Fatto questo, le ragioni potrebbero essere le seguenti:
1. WordPress – Il primo motivo e il più banale di tutti: se utilizzate WordPress, andate nel menù “impostazioni”, sotto la voce “lettura”. Lì c’è un piccolissimo flag che può impedire la scansione del sito. La voce è questa:
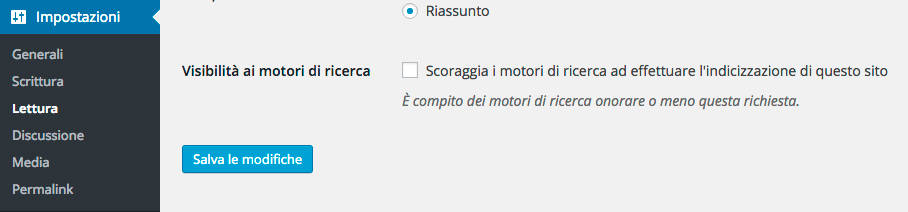
Se c’è, eliminatela immediatamente!
2. htaccess – Se il vostro sito web gira su un server Apache, sappiate che questo file può contenere configurazioni in grado di redigere il traffico verso altri domini, impedire l’indicizzazione e molto altro. È un file invisibile contenuto nella cartella pubblica del web server dove risiede il sito.
3. Meta Tags – a volte vengono dimenticati, ma possono essere insidiosi e dannosi. Sono i tag contenuti nell’intestazione delle pagine web. Possono contenere un po’ di tutto, compresi i tag per impedire al motore di ricerca di scansionare le nostre pagine. L’istruzione incriminata è la seguente:
<META NAME=”ROBOTS” CONTENT=”NOINDEX, NOFOLLOW”>
Quindi fateci attenzione, se la trovate nelle vostre pagine, ecco spiegato il perché non venite presi in considerazione da Google. Come fate a controllare? Semplice, basta un browser come Chrome. Quando siete sulla pagina che vorrete controllare, cliccate col tasto destro in un qualsiasi punto e selezionate dalla tendina “ispeziona elemento”. Vi si aprirà uno strumento attraverso cui potrete controllare il codice della pagina (insieme ad un sacco i alte cose). Se la riga incriminata c’è, bisognerà rimuoverla a mano dal codice sorgente.
4. Robots.txt – Questo è un file fatto per comunicare espressamente con il crawler, lo spider che scansiona il sito per indicizzarlo. Se c’è una riga come questa:
User-agent: * Disallow: /
Significa che state scoraggiando i motori di ricerca dalla scansione. Quindi vale quanto detto prima, rimuoverla!
5. Parametri URL – È una funzione della Search Console di Google. Attraverso questa funzionalità si possono indicare a Google diversi criteri per indicizzare i link dinamici. Bisogna fare molta attenzione ad utilizzarli, come espressamente indicato:
Utilizza questa funzione soltanto se sei sicuro del funzionamento dei parametri. L’errata esclusione degli URL potrebbe comportare la scomparsa di molte pagine dai risultati di ricerca.
6. Dominio – Cosa succede se acquistate un dominio che precedentemente è stato usato da malintenzionati per generare spam? Cose non simpatiche, ovviamente. Certo è una possibilità abbastanza remota, ma esiste, soprattutto con i domini .com. Cosa fare? C’è un’unica cosa, chiede a Google di riconsiderare la reputazione del dominio, con una Richiesta di riconsiderazione.
7. Pagerank – Sapete cos’è il Pagerank? È un metro di valutazione che google assegna alle vostre pagine, simile al Domainrank, che è la stessa valutazione, applicata però al dominio. Il numero di pagine scansionate, può dipendere anche dal Pagerank ed essere in qualche modo proporzionale.
fonte: https://www.stonetemple.com/matt-cutts-interviewed-by-eric-enge-2/
8. Sitemap – infine l’ultima speranza: la sitemap. Controllate costantemente la Search Console per monitorare gli errori rilevati. Potrebbe esserci qualche problema legato alla scansione di vecchie pagine che non avete considerato. Controllate gli errori, segnalate la loro correzione a Google e pulite le URL non può esistenti, magari con un redirect 301.
Photo credit: disparkys via VisualHunt / CC BY-ND
Fonte: Moz.com